
1. 函数式数据处理
行为参数化
行为参数化是一种编程范式,它允许方法的行为通过参数的形式传递和修改。这种技术在处理变化的需求时非常有用,因为它使得代码更加灵活,能够适应不同的行为而无需修改方法本身。行为参数化是函数式编程思想在面向对象编程语言中的一种体现,特别是在Java 8中,通过使用Lambda表达式和方法引用,行为参数化变得更加简单和直观。
Lambda
parameters -> expression 或 (parameters)->{statement;}
- 当 Lambda 表达式被用在一个期望
void返回类型的上下文时,表达式的返回值会被忽略,而表达式本身会被当做一个语句来执行. - 如果 Lambda 允许捕获可改变的局部变量,就会引发线程不安全的新可能性.
函数式接口
定义
- 只定义一个抽象方法的接口
- 使用
@FunctionalInterface注解函数式接口 - 只有在接受函数式接口的地方才可以使用 lambda 表达式
例子
Predicate
- Predicate 通常用于过滤数据或匹配数据
| |
Consumer
- 适用于需要访问对象的操作中,比如从集合中的每个元素中提取信息或者对每个元素应用某个操作。
| |
Function
Function接口非常适用于转换数据、从一种类型映射到另一种类型的场景。- 这里,
@FunctionalInterface注解表明这是一个函数式接口,而接口中的apply方法是要实现的抽象方法。apply方法接受一个类型为T的参数,并返回一个类型为R的结果。
| |
Function接口中的compose、andThen和identity方法使得函数式编程在Java中更加强大和灵活。
andThen
andThen方法用于将两个Function实例串联起来,其中第一个函数的输出作为第二个函数的输入。其签名如下:
| |
示例
假设我们有两个函数,一个将字符串转换为大写,另一个计算字符串的长度:
| |
compose
compose方法与andThen相反,它用于先执行作为参数传入的函数,然后执行调用compose的函数。其签名如下:
| |
示例
使用上面相同的函数,但这次我们改用compose来实现:
| |
identity
identity方法返回一个不进行任何操作的Function,即直接返回输入参数。这在需要传递一个原样输出的函数时非常有用。其签名如下:
| |
示例
| |
方法引用
方法引用的三种类型
- 指向静态方法的方法引用
- 指向任意类型实例方法的方法引用
- 指向现有对象的实例方法的方法引用
指向静态方法的方法引用
假设我们有一个静态方法
static int findLength(String s),它返回一个字符串的长度:1 2 3 4 5public class Utils { public static int findLength(String s) { return s.length(); } }使用
Function<T,R>和方法引用:1Function<String, Integer> lengthFunction = Utils::findLength;指向任意类型实例方法的方法引用
如果我们想引用
String类的length()实例方法:1Function<String, Integer> lengthFunction = String::length;这里不需要具体的实例,我们直接通过类名引用实例方法。
指向现有对象的实例方法的方法引用
如果我们有一个现有的对象,比如
List<String>,并想引用它的size方法:1 2List<String> list = Arrays.asList("apple", "banana", "cherry"); Supplier<Integer> sizeSupplier = list::size;这里
Supplier<T>是另一个函数式接口,它不接受参数但是返回一个结果。
Stream
流只能消费一次
流是内部迭代
流的使用包括三件事
- 一个数据源(如集合)来执行一个查询。
- 一个中间操作链,形成一条流的流水线。
- 一个终端操作,执行流水线,并生成结果
你可以利用
reduce方法将流中所有的元素迭代合并成一个结果,例如求和或查找最大 元素。filter和map等操作是无状态的,它们并不存储任何状态。reduce等操作要存储状态才 能计算出一个值。sorted和distinct等操作也要存储状态,因为它们需要把流中的所 有元素缓存起来才能返回一个新的流。这种操作称为有状态操作。
流有三种基本的原始类型特化:
IntStream、DoubleStream和LongStream。它们的操 作也有相应的特化。流不仅可以从集合创建,也可从值、数组、文件以及iterate与generate等特定方法 创建。
无限流是没有固定大小的流。
Java Streams API常用操作
| 类别 | 操作 | 描述 |
|---|---|---|
| 筛选和切片 | filter | 对流中的元素进行筛选,只保留满足谓词的元素。 |
distinct | 通过流所生成元素的 hashCode() 和 equals() 去除重复元素。 | |
skip | 跳过流中的前N个元素。 | |
limit | 截断流,使其元素不超过给定数量。 | |
| 转换 | map | 对流中的每个元素应用函数,将其转换成其他形式或提取信息。 |
flatMap | 将流中的每个值都换成另一个流,然后把所有流连接起来成为一个流。 | |
| 查找和匹配 | findFirst | 返回流中的第一个元素,如果流为空,返回空的Optional。 |
findAny | 返回流中的任意元素,如果流为空,返回空的Optional。 | |
allMatch | 检查流中的元素是否都满足给定的谓词。 | |
noneMatch | 检查流中的元素是否都不满足给定的谓词。 | |
anyMatch | 检查流中是否至少有一个元素满足给定的谓词。 | |
| 归约 | reduce | 将流中元素反复结合起来,得到一个值。 |
| 有状态操作 | sorted | 流中元素按自然顺序排序或按给定的比较器排序。 |
distinct | 通过流所生成元素的 hashCode() 和 equals() 去除重复元素。 | |
| 原始类型流 | IntStream, DoubleStream, LongStream | 基本类型的流,提供了额外的数值计算相关的方法。 |
| 流的创建 | 从集合、值、数组、文件创建 | 流可以通过集合的 stream() 方法,Arrays.stream,以及 Files.lines 等方法创建。 |
iterate 和 generate | 用于创建无限流。 |
summarizingLong、summarizingDouble
summarizingLong和summarizingDouble是两个非常有用的收集器(Collectors),它们能够对流中元素的某个长整型或双精度属性进行汇总统计。这些收集器生成的是LongSummaryStatistics或DoubleSummaryStatistics实例,分别用于长整型和双精度值的统计信息,包括元素数量、总和、最小值、最大值以及平均值。
joining
joining是Java中java.util.stream.Collectors类提供的一种工厂方法,用于将流中的元素在遍历过程中合并成一个字符串。这个方法非常适合在处理字符串集合或者需要将对象转换为字符串并连接起来的情况。joining方法有几个重载版本,可以根据需要选择使用。
1.无参版本
当不需要在连接的字符串之间添加分隔符、前缀或后缀时,可以使用最简单的形式:
| |
这将简单地将输入元素连接成一个字符串。
示例
| |
2.带有分隔符的版本
如果想要在每个元素之间添加一个分隔符,可以使用带有一个字符串参数的joining:
| |
示例
| |
3.带有分隔符、前缀和后缀的版本
最完整的joining版本允许在结果字符串的开始和结束添加前缀和后缀,同时在元素之间添加分隔符:
| |
示例:
| |
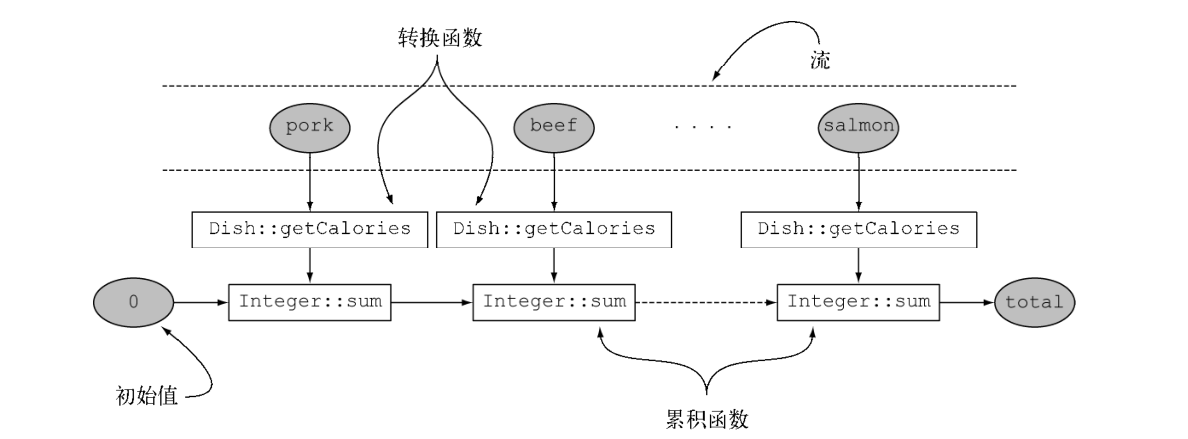
广义的归约汇总
Collectors.reducing 工厂方法是所有这些特殊情况的一般化
第一个参数是归约操作的起始值
第二个参数就是转换函数
第三个参数是累积函数
| |
groupingBy
| |
工作原理
- 分类:对流中的每个元素使用分类函数
classifier,根据其返回值进行分组。这个返回值决定了元素属于哪个分组键K。 - 收集:对于每个分组,使用提供的下游收集器
downstream对该分组中的元素进行进一步处理,生成结果类型D。 - 结果映射:最终,方法生成一个映射
Map<K, D>,其中每个键K(分组标准)都映射到一个D类型的值(下游收集器的结果)。
Function.identity()
通过返回一个简单的恒等函数,它允许保持元素不变或作为原始形式传递,同时满足函数式接口的需求。
| |
parallel(并行流)
parallel 流转换成并行流
| |
流的数据源和可分解性
| 类型 | 可分解性 |
|---|---|
| ArrayList | 较佳 |
| LinkedList | 差 |
| IntStream.range | 较佳 |
| Stream.iterate | 差 |
| HashSet | 好 |
| TreeSet | 好 |
高效使用并行流
通过测量耗时判断是否使用
留意装箱,自动装箱和拆箱操作会大大降低性能
limit和findFirst等依赖于元素顺序的操作,它们在并行流上执行的代价非常大对于较小的数据量,选择并行流几乎从来都不是一个好的决定
考虑终端操作中合并步骤的代价是大是小,如果这一步代价很大,那么组合每个子流产生的部分结果所付出的代价就可能会超出通过并行流得到的性能提升
分支/合框架
Java 8 引入了分支/合并框架(Fork/Join Framework),这是一个用于并行执行任务的框架,旨在充分利用多核处理器的计算能力。它是一种实现了工作窃取算法(work-stealing algorithm)的框架,允许多个处理器核心更高效地处理大量任务,尤其是那些可以递归分解为更小任务的工作。
核心概念
- Fork:将一个大任务分解成若干个小任务,这些小任务可以并行执行。“Fork"是这个过程的术语,意味着"分支"出新的子任务。
- Join:等待分支出去的任务完成,并将结果合并起来。“Join"指的是将这些并行执行的任务的结果合并到一起,完成整个任务。
关键组件
- ForkJoinPool:这是执行ForkJoinTask任务的线程池。它使用工作窃取算法来优化任务的执行,使得所有线程都尽可能保持忙碌状态。
- ForkJoinTask:这是要执行的任务的基类。有两个重要的子类:
- RecursiveAction:用于没有返回结果的任务。
- RecursiveTask
:用于有返回结果的任务。
工作窃取算法
工作窃取算法是分支/合并框架的核心。每个处理器都有自己的任务队列。当一个处理器完成了自己队列中的所有任务后,它可以随机选择一个其他处理器,“窃取"一部分任务来执行。这种方法提高了线程之间的工作负载均衡,减少了闲置时间
Spliterator
Spliterator是Java 8中引入的一个接口,设计用来进一步提高并行处理能力。它在java.util包中,主要用于遍历和分割数据源,以便于进行并行计算。与Iterator相比,Spliterator提供了更多的功能,特别是对于并行迭代操作而言。
关键方法
Spliterator接口定义了几个关键方法:
- tryAdvance(Consumer<? super T> action):如果剩余元素存在,则对下一个元素执行给定的操作,并返回
true;否则返回false。这类似于Iterator的hasNext和next方法的结合体。 - forEachRemaining(Consumer<? super T> action):对剩余每个元素执行给定的操作,直到所有元素都被处理或操作抛出异常。
- trySplit():尝试分割此
Spliterator,以便部分元素由当前Spliterator处理,而另一部分元素由新的Spliterator处理。这是并行处理的关键。 - estimateSize():返回此
Spliterator中剩余元素的估计数量。 - characteristics():返回此
Spliterator的特征值,这是一个位模式,表示该Spliterator的属性集。
2.高效 Java8 编程
Lambda 表达式优化代码
用Lambda表达式取代匿名类
原代码使用匿名类
| |
重构后使用Lambda表达式
| |
用方法引用重构Lambda表达式
原Lambda表达式代码
| |
重构后使用方法引用
| |
用Stream API重构命令式的数据处理
命令式编程风格(原代码)
| |
重构后使用Stream API
| |
使用Lambda表达式改进代码封装性和可读性
如果你发现需要频繁地从客户端代码查询对象状态,仅为了调用该对象的一个方法,可以通过接收Lambda或方法引用作为参数的方式来改进。
重构前的代码
| |
改进后的代码
定义一个新的日志方法,接受一个Supplier<String>类型的Lambda表达式作为参数,这样可以延迟消息构建的过程,只有在日志器启用的情况下才进行:
| |
然后客户端代码可以这样调用:
| |
这样,客户端代码就不需要直接查询日志器的状态了。通过将参数构建(或者说是计算)延迟到确实需要日志消息的时刻,提高了代码的封装性和可读性,同时也避免了在日志器未启用时不必要的字符串拼接操作。
重构|调试|测试
延迟执行和环绕执行
延迟执行(Lazy Execution) 延迟执行是编程中的一种策略,其中计算或代码执行被推迟到其结果实际需要的那一刻。这种策略在处理大量数据或进行资源密集型操作时特别有用,因为它可以提高应用程序的效率和响应能力。在Java中,延迟执行常常与流(Streams)、延迟加载和懒惰初始化等概念相关联。
环绕执行(Around Execution) 环绕执行是一种编程模式,通常用于资源管理、监控、日志记录或安全控制等场景。这种模式允许开发者在方法执行前后执行一些预处理和后处理代码,而不需要修改原有方法的代码。在Java中,环绕执行经常通过使用代理(Proxy)、装饰器模式或AOP(面向切面编程)框架如Spring AOP来实现。
Lambda 与 设计模式
- 策略模式
- 模版方法
- 观察者模式
- 责任链模式
- 工厂模式
peek
peek 是 Stream API 中的一个中间操作,它允许你在不改变流中元素的情况下,对每个元素执行操作,主要用于调试目的,因为它允许查看流中的元素而不会干扰后续的操作。
| |
默认方法
目的: 它让类可以自动地继承接口的一个默认实现,它让类库的设计者放心地改进应用程序接口,无需担忧对遗留代码的影响。
三种兼容性
二进制级的兼容(Binary Compatibility)
- 定义:如果一个应用程序在升级了使用的库或组件之后,不需要重新编译,仍然可以正常运行,那么这个库或组件的新版本就被认为是与旧版本在二进制级别上兼容的。
- 关键点:这种兼容性确保了编译后的程序代码(二进制代码)在库或组件更新后仍可运行,无需任何修改。这通常涉及到API中函数的签名、数据类型的布局和大小、以及类成员的顺序和可访问性等方面。
源代码级的兼容(Source Compatibility)
- 定义:如果在库或组件更新后,应用程序的源代码不需要修改就能重新编译并正常运行,那么这个更新被认为是源代码级别上兼容的。
- 关键点:这种兼容性强调源代码在经历库或组件的版本升级后仍旧可以不经修改直接编译通过。它关注于API的使用方式,包括函数、类的命名,参数的类型和数量,返回值类型等。
函数行为的兼容(Functional Behavior Compatibility)
- 定义:如果库或组件的功能更新后,其公开的函数或方法的行为(包括副作用、执行结果和性能特征)保持不变,那么这个更新被认为保持了函数行为的兼容。
- 关键点:这种兼容性确保了即使库或组件的内部实现发生变化,对外提供的功能和预期的行为没有改变。对于使用该库或组件的开发者来说,他们可以预期即便更新了依赖,其应用程序的功能表现不会受到影响。
默认方法的使用模式
- 可选方法
放置一个空的实现,减少无效的模版代码。
| |
- 行为的多继承
默认方法提供了一种多重继承的行为实现机制。类可以从多个接口继承默认方法的实现,解决了之前Java中的多重继承限制。在遇到多个接口定义相同默认方法的情况下,实现类必须覆盖该方法,以解决冲突。
方法解决冲突
- 类中的方法优先级最高。类或父类中声明的方法的优先级高于任何声明为默认方法的优先级。
- 如果无法依据第一条进行判断,那么子接口的优先级更高:函数签名相同时,优先选择拥有最具体实现的默认方法的接口,即如果B继承了A,那么B就比A更加具体。
- 最后,如果还是无法判断,继承了多个接口的类必须通过显式覆盖和调用期望的方法。
CompletableFuture
CompletableFuture 提供了丰富的方法来处理异步编程的需求。以下是一些最常用的方法:
创建方法
static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier)- 异步地执行一个 Supplier 供给型函数。
static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier, Executor executor)- 在指定的 Executor 中异步地执行一个 Supplier 函数。
转换和处理结果的方法
<U> CompletableFuture<U> thenApply(Function<? super T,? extends U> fn)- 当 CompletableFuture 完成时,将结果传递给提供的函数。
<U> CompletableFuture<U> thenApplyAsync(Function<? super T,? extends U> fn)- 异步地应用一个函数到 CompletableFuture 的结果上。
<U> CompletableFuture<U> thenApplyAsync(Function<? super T,? extends U> fn, Executor executor)- 在指定的 Executor 中异步地应用一个函数到 CompletableFuture 的结果上。
消费结果的方法
CompletableFuture<Void> thenAccept(Consumer<? super T> action)- 当 CompletableFuture 完成时,给定的动作会被执行,消费 CompletableFuture 的结果。
CompletableFuture<Void> thenAcceptAsync(Consumer<? super T> action)- 异步地消费 CompletableFuture 的结果。
CompletableFuture<Void> thenAcceptAsync(Consumer<? super T> action, Executor executor)- 在指定的 Executor 中异步地消费 CompletableFuture 的结果。
组合 CompletableFuture 的方法
<U,V> CompletableFuture<V> thenCombine(CompletionStage<? extends U> other, BiFunction<? super T,? super U,? extends V> fn)- 当两个 CompletionStage 都正常完成时,将它们的结果传递给提供的函数。
<U,V> CompletableFuture<V> thenCombineAsync(CompletionStage<? extends U> other, BiFunction<? super T,? super U,? extends V> fn)- 异步地组合两个 CompletionStage 的结果,并应用函数。
<U,V> CompletableFuture<V> thenCombineAsync(CompletionStage<? extends U> other, BiFunction<? super T,? super U,? extends V> fn, Executor executor)- 在指定的 Executor 中异步地组合两个 CompletionStage 的结果,并应用函数。
异常处理的方法
CompletableFuture<T> exceptionally(Function<Throwable, ? extends T> fn)- 当 CompletableFuture 完成异常时,提供的函数将被调用,可以返回替代的结果。
<U> CompletableFuture<U> handle(BiFunction<? super T, Throwable, ? extends U> fn)- 当 CompletableFuture 完成时(无论正常还是异常),提供的函数都会被调用,并允许返回结果或抛出异常。
<U> CompletableFuture<U> handleAsync(BiFunction<? super T, Throwable, ? extends U> fn)- 异步地处理 CompletableFuture 的完成(无论正常还是异常)。
<U> CompletableFuture<U> handleAsync(BiFunction<? super T, Throwable, ? extends U> fn, Executor executor)- 在指定的 Executor 中异步地处理 CompletableFuture 的完成(无论正常还是异常)。
并行——使用流还是CompletableFutures?
- 如果你进行的是计算密集型的操作,并且没有I/O,那么推荐使用Stream接口,因为实现简单,同时效率也可能是最高的(如果所有的线程都是计算密集型的,那就没有必要创建比处理器核数更多的线程)。
- 反之,如果你并行的工作单元还涉及等待I/O的操作(包括网络连接等待),那么使用CompletableFuture灵活性更好,你可以像前文讨论的那样,依据等待/计算,或者W/C的比率设定需要使用的线程数。这种情况不使用并行流的另一个原因是,处理流的流水线中如果发生I/O等待,流的延迟特性会让我们很难判断到底什么时候触发了等待。****
新的日期和时间API
LocalDate
- 内容:表示不带时间的日期,例如
2023-03-30。 - 常用API
now():获取当前日期。of(year, month, day):创建一个指定年月日的日期。plusDays(long daysToAdd)、minusDays(long daysToSubtract):日期加减操作。getDayOfWeek()、getMonth()、getYear():获取日期的各个部分。
LocalTime
- 内容:表示不带日期的时间,例如
10:15:30。 - 常用API
now():获取当前时间。of(hour, minute, second):创建一个指定时分秒的时间。plusHours(long hoursToAdd)、minusHours(long hoursToSubtract):时间加减操作。getHour()、getMinute()、getSecond():获取时间的各个部分。
Instant
- 内容:表示时间线上的一个瞬时点,它是以 Unix 时间戳的形式来存储的。
- 常用API
now():获取当前的瞬时点。ofEpochMilli(long epochMilli):根据 Unix 时间戳创建 Instant 实例。plusMillis(long millisToAdd)、minusMillis(long millisToSubtract):瞬时点的加减操作。
Duration
- 内容:表示两个时刻之间的时间量,以秒和纳秒为单位。
- 常用API
between(Temporal startInclusive, Temporal endExclusive):计算两个时间点之间的 Duration。ofDays(long days)、ofHours(long hours)、ofMinutes(long minutes):创建指定时间长度的 Duration。plus(Duration duration)、minus(Duration duration):Duration 的加减操作。
Period
- 内容:表示两个日期之间的年月日的时间量。
- 常用API
between(LocalDate startDateInclusive, LocalDate endDateExclusive):计算两个日期之间的 Period。ofYears(int years)、ofMonths(int months)、ofDays(int days):创建指定时间长度的 Period。plus(Period period)、minus(Period period):Period 的加减操作。
附录
常用的函数式接口
| 接口名 | 方法签名 | 用途 | 其他方法 |
|---|---|---|---|
Consumer<T> | void accept(T t) | 接受单个输入参数并且不返回结果的操作(消费者)。 | N/A |
Supplier<T> | T get() | 无需输入参数,返回一个结果。 | N/A |
Function<T, R> | R apply(T t) | 接受一个输入参数,返回一个结果。 | default <V> Function<V, R> compose(Function<? super V, ? extends T> before)default <V> Function<T, V> andThen(Function<? super R, ? extends V> after)static <T> Function<T, T> identity() |
Predicate<T> | boolean test(T t) | 确定类型为T的对象是否满足某约束,并返回boolean值。 | default Predicate<T> and(Predicate<? super T> other)default Predicate<T> negate()default Predicate<T> or(Predicate<? super T> other) |
BiConsumer<T,U> | void accept(T t, U u) | 接受两个输入参数的操作,并且不返回任何结果。 | N/A |
BiFunction<T,U,R> | R apply(T t, U u) | 接受两个输入参数的函数,并且返回一个结果。 | N/A |
UnaryOperator<T> | 继承自Function | 一种特殊的Function,输入参数类型和返回类型相同。 | static <T> UnaryOperator<T> identity() |
BinaryOperator<T> | 继承自BiFunction | 一种特殊的BiFunction,两个输入参数和返回类型相同。 | N/A |
Optional 类主要方法
| 方法名 | 描述 |
|---|---|
empty() | 创建一个空的 Optional 实例。 |
of(T value) | 创建一个包含非空值的 Optional 实例。如果 value 为 null,则抛出 NullPointerException。 |
ofNullable(T value) | 创建一个 Optional 实例,如果指定的值为 null,则返回一个空的 Optional。 |
isPresent() | 如果值存在且非空,则返回 true;否则返回 false。 |
isEmpty() | Java 11 中引入,如果值不存在或为空,则返回 true;否则返回 false。 |
get() | 如果值存在,则返回该值;否则抛出 NoSuchElementException。 |
ifPresent(Consumer<? super T> action) | 如果值存在,执行给定的操作。 |
ifPresentOrElse(Consumer<? super T> action, Runnable emptyAction) | Java 9 中引入,如果值存在,执行给定的操作;否则执行另一个操作。 |
orElse(T other) | 如果有值则返回该值,否则返回一个默认值。 |
orElseGet(Supplier<? extends T> other) | 如果有值则返回该值,否则返回一个由 Supplier 接口生成的值。 |
orElseThrow() | 如果有值则返回该值,否则抛出 NoSuchElementException。 |
orElseThrow(Supplier<? extends X> exceptionSupplier) | 如果有值则返回该值,否则抛出由提供的 Supplier 接口生成的异常。 |
filter(Predicate<? super T> predicate) | 如果有值且满足给定的条件,则返回包含该值的 Optional;否则返回一个空的 Optional。 |
map(Function<? super T,? extends U> mapper) | 如果有值,则对该值执行给定的映射函数,并返回一个 Optional 类型的结果。 |
flatMap(Function<? super T, ? extends Optional<? extends U>> mapper) | 如果有值,则将提供的 Optional 映射函数应用于该值,否则返回一个空的 Optional。 |
stream() | Java 9 中引入,如果有值则返回仅包含该值的顺序 Stream,否则返回一个空的 Stream。 |
PECS原则
一个好的经验法则是所谓的PECS原则(“Producer Extends, Consumer Super”),由Joshua Bloch提出:
- 如果你需要一个提供者(Producer),即希望从泛型数据类型中读取数据,使用
extends。 - 如果你需要一个消费者(Consumer),即希望写入数据到泛型数据类型中,使用
super。